Gaussian Processes (Theory)#
Here we follow chapter 6 of [Rasmussen and Williams, 2006]. The domain of discourse is a reproducing kernel Hilbert space (RKHS). We start with the appropriate definitions:
Definition 1 (Hilbert space)
A Hilbert space \(\mathcal{H}\) is a real or complex inner product space that is also a complete metric space with respect to the induced metric.
The relevant space here is that of \(L_2\) functions with the inner product, i.e. over the index space space of \(\mathcal{X} = \mathbb{R}\).
We include here the possibility of a “metric” function \(g(x)\) to be discussed later. The notion of completeness means that every Cauchy sequence of points in \(\mathcal{H}\) has a limit also in \(\mathcal{H}\).
Definition 2 (Reproducing kernel Hilbert space (RKHS))
A Hilbert space \(\mathcal{H}\) is called a reproducing kernel Hilbert space (RKHS) if there is a function \(k: \mathcal{X}\times\mathcal{X} \mapsto \mathbb{C}\) called the reproducing kernel which satisfies, for all \(\vect{x} \in \mathcal{X}\):
\(k(\vect{x}, \cdot): \mathcal{X}\mapsto \mathbb{C} \in \mathcal{H}\)
\(\braket{k(\cdot,\vect{x}), f(\cdot)} = f(\vect{x})\).
In our example space of \(L_2\) functions, the second condition is:
As a consequence of the Moore–Aronszajn theorem, the reproducing kernel \(k(\cdot, \cdot)\) is unique in the RKHS, and every symmetric positive definite kernel \(k: \mathcal{X}\times \mathcal{X} \mapsto \mathbb{C}\), there is a unique Hilbert space of functions on \(\mathcal{X}\) for which \(k\) is a reproducing kernel.
To clarify this, consider functions sampled at a discrete set of points \(x_i\) such that \(f_i = f(x_i)\) can be thought of as a finite-dimensional complex vector \(\vect{f}\). To be definite, consider equally spaced points with spacing \(\delta_{x}\) so that the inner-product is:
where the metric function \(g(x)\) and integration measure have been packaged into the matrix
Here we sometimes call the matrix \(\mat{G}\) “the metric”, and we can generalize to situations where it is not necessarily diagonal. However, to be a proper inner product space, \(\mat{G}\) must be Hermitian positive definite. We can also represent the kernel \(k(\cdot, \cdot)\) as a matrix:
The finite dimensionality removes any subtleties associated with completeness, etc., so we can simply state that a reproducing kernel \(\mat{K}\) satisfies:
I.e., the kernel \(\mat{K}\) is just the adjoint of the inverse metric. The Moore–Aronszajn theorem is just stating that, for every choice of symmetric positive definite kernel, one obtains a unique inner product space with metric matrix \(\mat{G}\), and vice versa. The symmetric positive definite property ensures that the mapping is one-to-one.
Incomplete#
In physics, we usually hide this distinction using bra-ket notation with kets (vectors) \(\ket{a} \in \mathcal{H}\), and defining the bras (forms):
with vectors \(\ket{f} \in \mathcal{H}\) (using bra-ket notation), and kernels just linear operators \(\op{K}\). Numbers like \(f(\vect{x}) \equiv \braket{x|f}\) are just the coefficients of the vector \(\ket{f}\) in some bass \(\ket{x}\).
I.e., the operator \(\op{K}\) is just the identify on the vector space. This kind of throws out the baby with the bath-water. To see why this is important, consider again
Example Problem: Regression#
To make the core ideas here concrete, we consider the problem of trying to learn about a function \(y = f(x)\) where \(f: \mathbb{R}\rightarrow \mathbb{R}\) given some data \(D=\{(x_i, y_i)\} = (\vect{x}, \vect{y})\) distributed as a multivariate Gaussian distribution \(\vect{y} \sim \N(\vect{\mu}, \mat{C})\) with probability distribution function (PDF)
The following provide alternative, but ultimately equivalent, viewpoints of this problem:
Linear least-squares fitting. The idea here is to use a set of basis functions \(\phi_n(x)\) and express:
\[\begin{gather*} f_{\vect{a}}(x) = \sum_{n} a_n \phi_n(x). \end{gather*}\]Using Bayes’ theorem, if we have a prior for the parameters \(\vect{a} \sim p(\vect{a})\), then our posterior is:
\[\begin{gather*} p(\vect{a}|D) \propto \overbrace{\mathcal{L}(\vect{a}|D)}^{p(D|\vect{a})}p(\vect{a}). \end{gather*}\]Here the likelihood function \(\mathcal{L}(\vect{a}|D) = p(D|\vect{a})\) is the probability of obtaining the data \(D\) if the true parameter values were \(\vect{a}\). Given our assumption above that \(\vect{y} \sim \N(\vect{\mu}, \mat{C})\), we have:
\[\begin{gather*} p(D|\vect{a}) = p_{\N(\vect{\mu}, \mat{C})}\Bigl(f_{\vect{a}}(\vect{x})\Bigr). \end{gather*}\]If the priors are also distributed as a multivariate Gaussian distribution \(\vect{a} \sim \N(\vect{\mu}_a, \mat{C}_a)\), then we can compute the posterior:
\[\begin{gather*} p(\vect{a}|D) \propto \overbrace{\mathcal{L}(\vect{a}|D)}^{p(D|\vect{a})}p(\vect{a}). \end{gather*}\]Gaussian Process.
Gaussian Processes#
In simple terms, a Gaussian process is just the generalization of a multivariate Gaussian distribution to infinite-dimensional spaces such as the space of functions. To say that a function \(f: \mathbb{R}\mapsto \mathbb{R}\) is distributed by a Gaussian process
means that, if \(f(x)\) is sampled at any finite set of points \(\vect{x}\) with \(y_i = f(x_i)\), then \(\vect{y}\) is distributed as multivariate Gaussian distribution \(\vect{y} \sim \N(\vect{\mu}, \mat{C})\) with probability distribution function (PDF)
I.e. \(\vect{\mu}\) is the vector of mean values and \(\mat{C}\) is the covariance matrix. The functions \(m(x)\) and \(\kappa(x, x')\) are simply the infinite-dimensional 1representations of these in the continuum limit.
Regression#
Gaussian processes can be used to perform a generalized linear regression for the function \(y=f(x)\). Consider the aforementioned tabulation \(D=\{(x_i, y_i)\}\) to be “data” from some experiment with correlated Gaussian errors \(\vect{y} \sim \N(\vect{\mu}, \mat{C})\). We can use Bayes’ theorem to update some prior distribution \(f\sim p(f)\):
If the prior is Gaussian process \(f \sim \GP[m(x), \kappa(x, x')]\), then we can compute the posterior analytically.
Details
To see how this works, consider a function \(y_n = f(x_n)\) tabulated at a set of \(N\) points \(x_{n \in \{0, 1, \dots N-1\}}\) with a Gaussian prior \(\vect{y} \sim \N(\vect{\mu}, \mat{C})\). Now consider data \(D\) consisting of a few points \(x_{i \in \{0, 1, M-1\}}\) with experimental errors \(\vect{y}_D \sim \N(\vect{\mu}_D, \mat{C}_D)\). Note, we have not specified which points are where, so we have organized the abscissa so that the experimental data are the first \(M\) points, which need not be adjacent.
We can now express \(\mat{C}\) is block diagonal form with the first block corresponding to the indices where we have data:
Organize the points so that the first Consider
Background#
Properties of Gaussian Distributions#
Here is a quick summary of the relevant properties of multivariate Gaussian distributions. See also Random Variables for additional details.
PDF#
The probability distribution function (PDF) for a vector \(\vect{y} \sim \N(\vect{\mu}, \mat{C})\) of variables \(\{y_i\}\) distributed as a multivariate Gaussian distribution (or multivariate normal distribution) is:
Here \(\vect{\mu}\) is the vector of mean values, and \(\mat{C}\) is the covariance matrix.
Product of PDFs#
The product of the PDFs of multivariate Gaussian distributions with symmetric covariances \(\mat{C} = \mat{C}^\dagger\) is a multivariate Gaussian distribution (but not normalized):
I.e. the sums of the inverse covariance matrices add.
Marginal Distribution#
Partition a multivariate Gaussian distribution \(\vect{y} \sim \N_{\vect{y}}(\vect{\mu},\mat{C})\) as
where \(\mat{C}_{ba} = \mat{C}_{ab}^\dagger\) for standard distributions \(\mat{C} = \mat{C}^{\dagger}\). The marginal distributions for each partition (integrating over the other variables) are:
I.e. the conditional covariance matrices are just the corresponding sub-blocks of the full covariance matrix.
Conditional Distributions#
Partition a multivariate Gaussian distribution \(\vect{y} \sim \N_{\vect{y}}(\vect{\mu},\mat{C})\) as
where we have partitioned the inverse covariance here \(\mat{C}^{-1}\) using the Schur complements \(\mat{C} / \mat{C}_{a}\) and \(\mat{C} / \mat{C}_{b}\) of the block matrix \(\mat{C}\):
I.e. the conditional inverse covariance matrices are just the corresponding sub-blocks of the full inverse covariance matrix.
Linear Combinations#
If \(\vect{x} \sim \N(\vect{\mu}_x, \mat{C}_x)\) and \(\vect{y} \sim \N(\vect{\mu}_y, \mat{C}_y)\) are independent, then \(\vect{z} = \mat{X}\vect{x} + \mat{Y}\vect{y}\) is distributed as:
Principle Components, Bases, and Metrics#
Consider a multivariate Gaussian distribution normal distribution \(\vect{y} \sim \N(\vect{\mu}, \mat{C})\). If we diagonalize the covariance matrix \(\mat{C} = \mat{U}\mat{D}\mat{U}^{\dagger}\):
then the columns of \(\mat{U} = [\uvect{u}_0 \; \uvect{u}_1\; \cdots]\) form an orthonormal basis that we can rescale into a set of orthogonal vectors \(\vect{u}_n = \sigma_n\uvect{u}_{n}\) such that
where \(\xi_n\) are independent random variables with a standard normal distribution (zero mean and unit covariance). The vectors \(\vect{u}_n\) or the pairs \((\uvect{u}_{n}, \sigma_n)\) are called the principle components. Note that this also follows from the property above of linear combinations of random variables (expressed as a sum of dyads):
A somewhat surprising result is that, if we relax the requirement that the vectors \(\vect{u}_n\) be orthogonal, then there are many similar decompositions of \(\vect{y}\) as a linear combination of independent standard normal variables:
where the vectors \(\vect{a}_n\) are linearly independent, but need not be orthogonal.
To see this, construct the singular value decomposition (SVD) for \(\mat{A}\):
If we are careful and arrange the singular values appropriately, then \(\mat{U}\) and \(\mat{D}\) here are the same as in the diagonalization of \(\mat{C}\), but the unitary matrix \(\mat{V}\) is arbitrary. Here we demonstrate numerically in 2D:
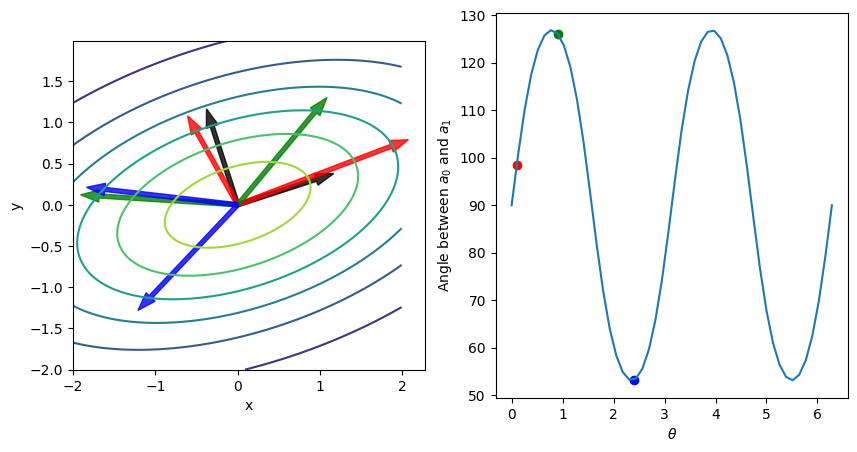
This figure shows contours from a bivariate normal distribution with orthogonal principle components \(\vect{u}_0\) and \(\vect{u}_1\) shown as black vectors. Several equivalent independent but non-orthogonal basis vectors \(\vect{a}_0\) and \(\vect{a}_1\) are shown in different colors. These are generated by a one-dimensional parameterization of the unitary matrix \(\mat{V}(\theta)\). In this case, we can choose any direction \(\uvect{a}_0\), but must construct \(\vect{a}_1\) carefully.
References#
[Gelman et al., 2013]: A good comprehensive reference. Available for non-commercial from the author’s webpage.
[Melendez et al., 2019]: An application to nuclear theory with associated code
gsum.[Rasmussen and Williams, 2006]: Another nice book that formed the basis for the implementations in scikit-learn.